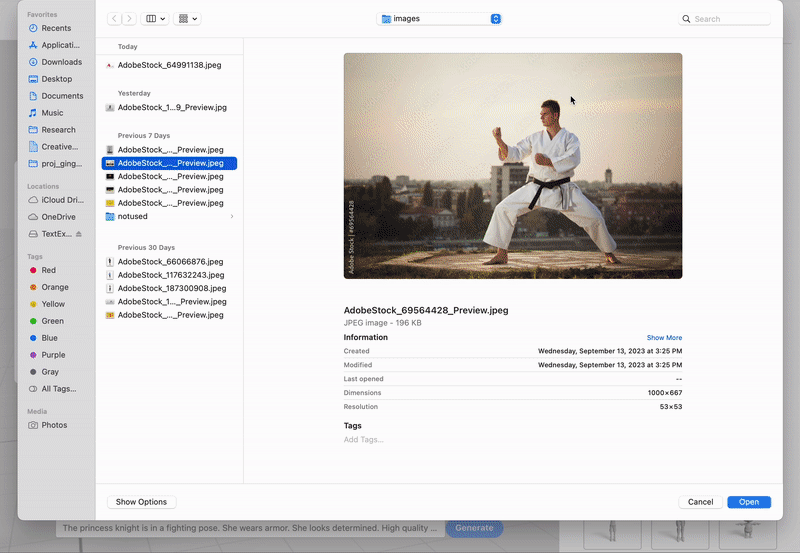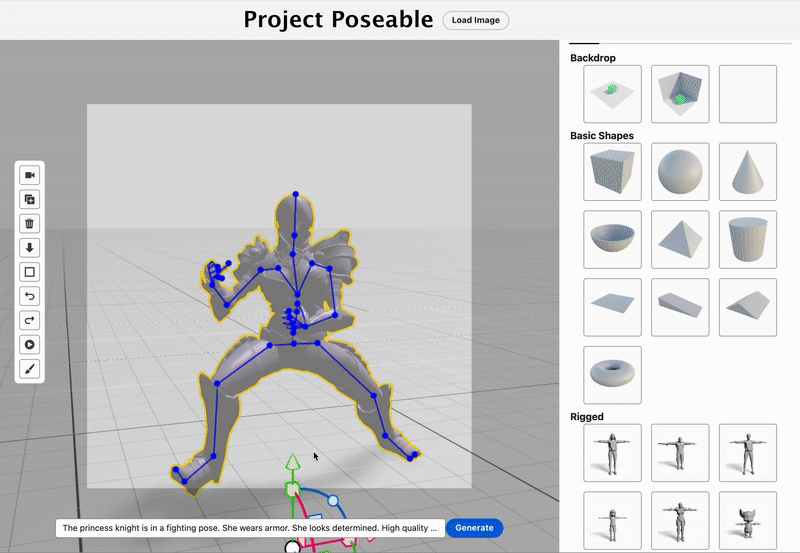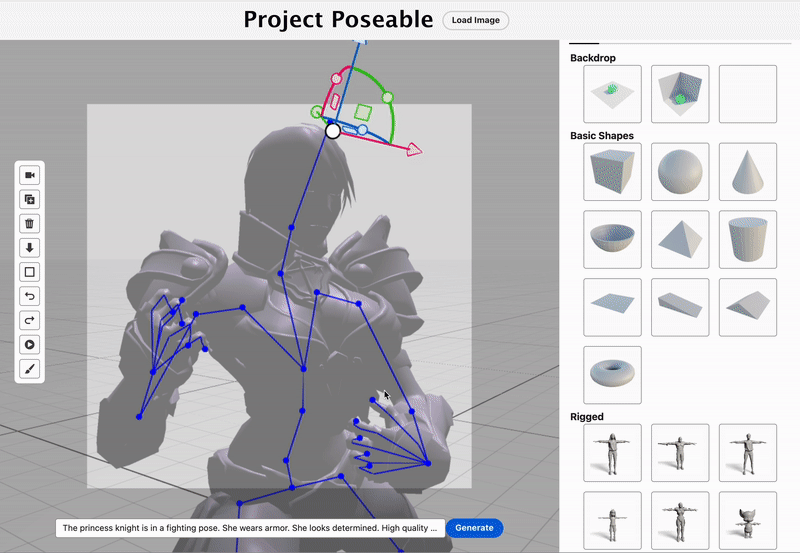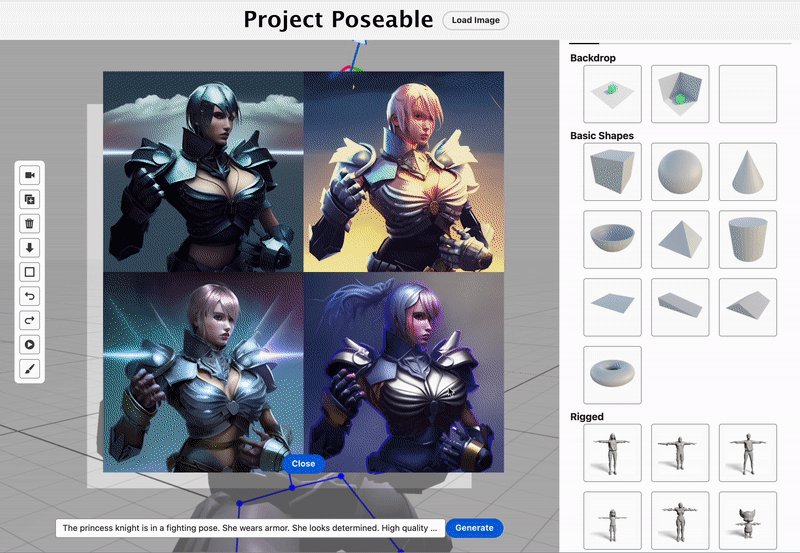
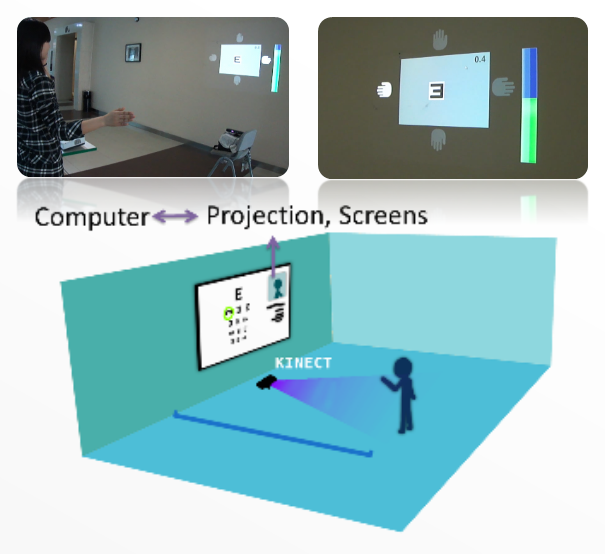
Yi Zhou
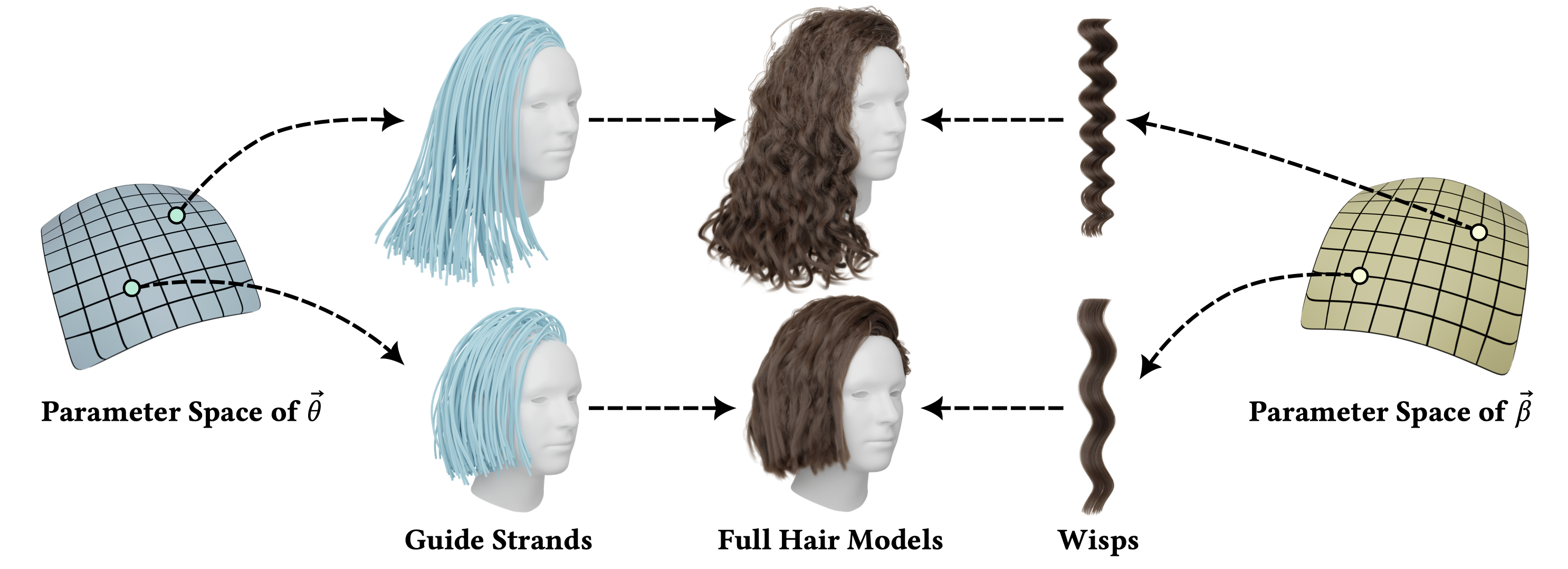
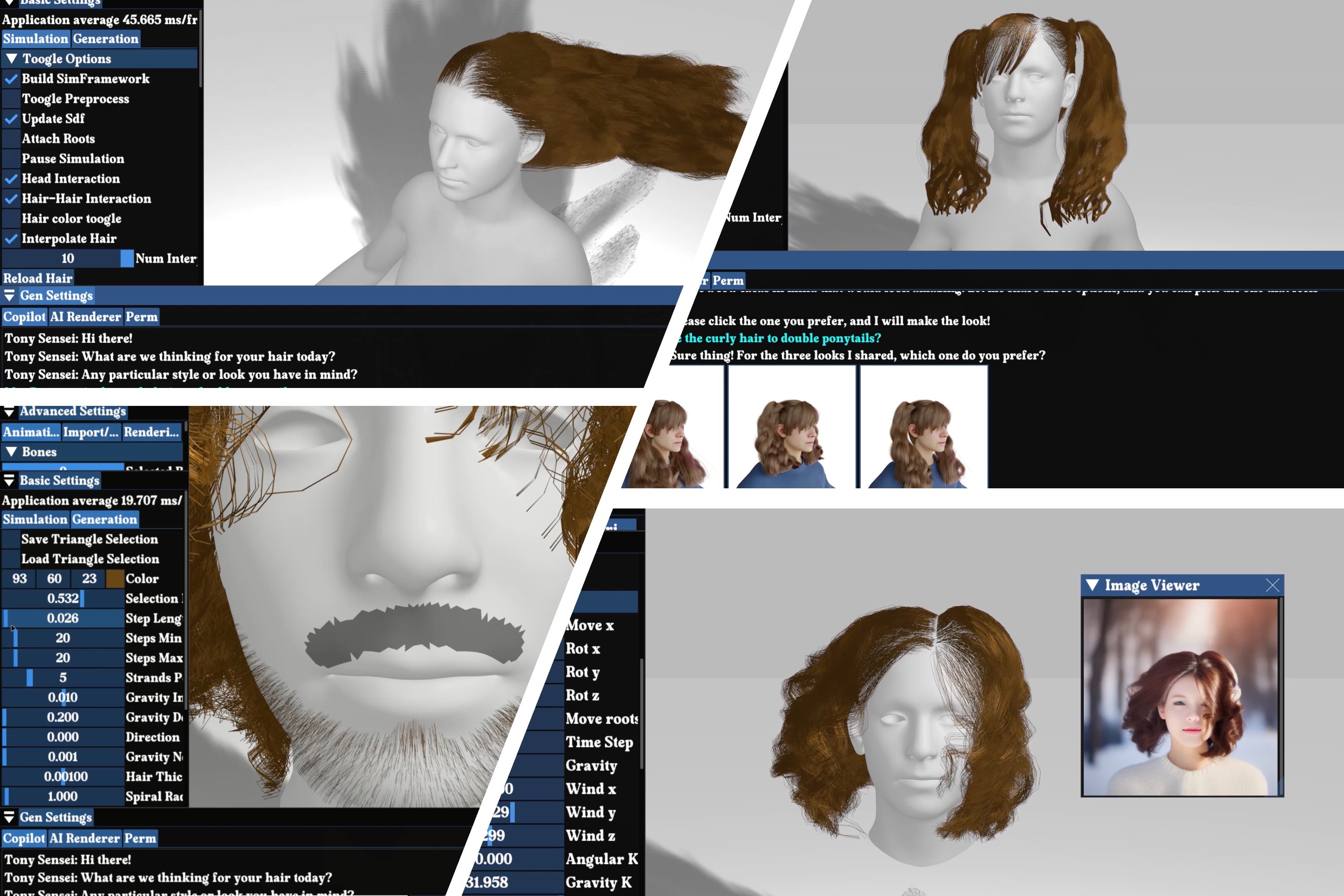
I am a senior AI scientist at Roblox. Previously, I am a research scientist at Adobe. I received my PhD from the University of Southern California under the supervision of Dr. Hao Li and my Master's and Bachelor's degrees from Shanghai Jiao Tong University under the supervision of Dr. Shuangjiu Xiao. My research focuses on autonomous 3D virtual human and 3D representation learning, specializing in differentiable geometry, 2D/3D human generation, motion synthesis, simulation and 4D Human-Object-Interaction. My biggest personal interests lie in creating AI-driven Avatars and the interaction between Avatars and humans now. I served on the Siggraph 2023, Siggraph Asia 2024 and 2025 Technical Papers Committee and 2025 Eurographics Short Paper Committee.
I am also an independent musician